How to import multiple (large) data files in R at once
I had a project where I had to import around 100 different files 30 times (from 30 folders), in order to do that, I used a function called fread from data.table package (a faster alternative to read.csv that can work with big files), dirLister (a free and simple tool), and sheets.google.com (any Excel-ish software will do).
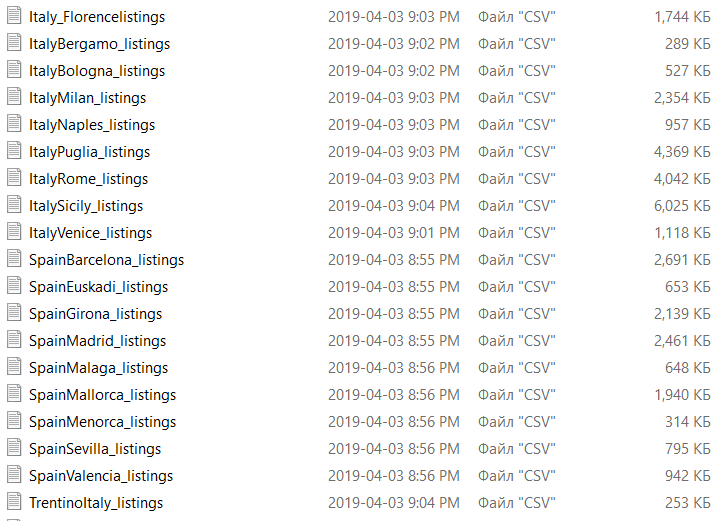
So, let’s assume we’ve got a folder with the following files:
I suggest to download and install dirLister, after launching the DirLister.exe file, navigate to the folder in Input tab.

Now switch to the Output tab, and choose where you want to save the filenames file, I chose Plain text (.txt) as an Output format and the same folder, then pressed Set as default options and Start.

The file with a list of folder file names will open (if you tick “Open outpute file/folder after list generation”), otherwise check the Output folder.

You can now copy the generated list in a Google Sheets file, where you are going to need a function called CONCATENATE.
Considering these are the column names in the .csv files, let’s say we only want to select columns id, host_id, price, and availability_365, so the respective column numbers will be: 1, 3, 9, 16.
NOTE: I’d advise to only import the columns that you need for your analysis as there are limits to either R or RAM. The rule is simple, the less data you load, the more files you can import.
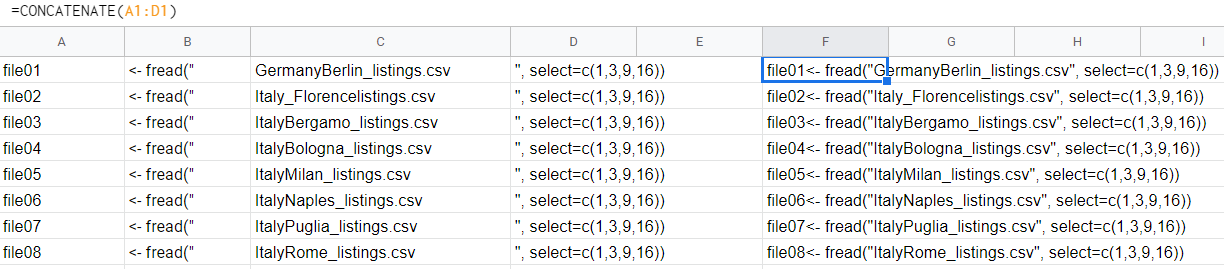
So I pasted the list in column C, filled the first 3 cells in column A, and then filled the first row; used CONCATENATE in column F to connect all the other columns in one cell, then stretched the cells to the end of column C
=CONCATENATE(A1:D1)
Open R and write the following:
install.packages("data.table") #if you don’t have the package preinstalled
library(data.table)
setwd("C://Users//ww//Documents//Data//InsideAirbnb")
You can copy and paste column F from Google Sheets to R now. Here’s what I got:
file01<- fread("GermanyBerlin_listings.csv", select=c(1,3,10,16))
file02<- fread("Italy_Florencelistings.csv", select=c(1,3,10,16))
file03<- fread("ItalyBergamo_listings.csv", select=c(1,3,10,16))
file04<- fread("ItalyBologna_listings.csv", select=c(1,3,10,16))
file05<- fread("ItalyMilan_listings.csv", select=c(1,3,10,16))
file06<- fread("ItalyNaples_listings.csv", select=c(1,3,10,16))
file07<- fread("ItalyPuglia_listings.csv", select=c(1,3,10,16))
file08<- fread("ItalyRome_listings.csv", select=c(1,3,10,16))
file09<- fread("ItalySicily_listings.csv", select=c(1,3,10,16))
file10<- fread("ItalyVenice_listings.csv", select=c(1,3,10,16))
file11<- fread("SpainBarcelona_listings.csv", select=c(1,3,10,16))
file12<- fread("SpainEuskadi_listings.csv", select=c(1,3,10,16))
file13<- fread("SpainGirona_listings.csv", select=c(1,3,10,16))
file14<- fread("SpainMadrid_listings.csv", select=c(1,3,10,16))
file15<- fread("SpainMalaga_listings.csv", select=c(1,3,10,16))
file16<- fread("SpainMallorca_listings.csv", select=c(1,3,10,16))
file17<- fread("SpainMenorca_listings.csv", select=c(1,3,10,16))
file18<- fread("SpainSevilla_listings.csv", select=c(1,3,10,16))
file19<- fread("SpainValencia_listings.csv", select=c(1,3,10,16))
file20<- fread("TrentinoItaly_listings.csv", select=c(1,3,10,16))
file21<- fread("UKBristol_listings.csv", select=c(1,3,10,16))
file22<- fread("UKEdinburgh_listings.csv", select=c(1,3,10,16))
file23<- fread("UKGreaterManchester_listings.csv", select=c(1,3,10,16))
file24<- fread("UKLondon_listings.csv", select=c(1,3,10,16))
file25<- fread("UKManchester_listings.csv", select=c(1,3,10,15))
allfiles <- rbind(file01, file02, file03, file04, file05, file06, file07, file08, file09,
file10, file11, file12, file13, file14, file15, file16, file17, file18,
file19, file20, file21, file22, file23, file24, file25)
Use rbind then to unite all the files into one dataset. This is the way I did it for over many times, I hope that this semiautomatic method helped you. There are other ways to get there as it’s mentioned in this discussion on Stackoverflow.