Sentiment Analysis of Russian Reviews to Senua’s Sacrifice in Python

A while ago I was sent an article with a great list of projects you can start coding while at home, there were 2 projects of interest, I wanted to learn how to build a web-scraper and I wanted to conduct a sentiment analysis.
At first, I was going to build a machine learning model to predict the ratings of book reviews. While building a web-scraper with BeautifulSoup, I encountered difficulties embodied within multiple review aggregation sites that wouldn’t allow me to collect data, they either were too popular, meaning, ready to counter my attempts to get data from there or built with Ajax (not supported by BeautifulSoup), so I avoided manual collection as it was my purpose to learn how to automate and build a web-scraper.
Then I thought about Russian cause we didn’t work with it during my studies at Praktikum and analyzing game reviews sounded even more exciting to me although I understood that there is rather a few reviews written in it. I started with kanobu.ru where I got around 70 reviews with ratings, so I started gathering as many reviews as I could and by the end of the day I got 140 reviews collected from various sites, I had to collect some manually from a place.
Never spend 6 minutes doing something by hand when you can spend 6 hours failing to automate it
— Zhuowei Zhang (@zhuowei) April 26, 2020
Even though I broke the rule, I did automate multiple sites with only a couple of reviews for the sake of practice.
The reason why I chose Hellblade: Senua’s Sacrifice is that I enjoyed the plot where the main character with a mental illness is Senua, a young lady set on a course to save her true love, a son of a Celtic chieftain named Dillion, from Hel, the foreign Scandinavian mythology’s underworld and bring him back to life (how many people would do that given the opportunity?), because of her mental illness, Senua is both guided and misguided by several voices throughout the whole journey. I also thought that its reception would possibly be ambiguous, as playing it was not a pleasant experience, rather a thrilling one and people may have mistaken it for a slasher (in the beginning I certainly did), there are no tutorials, and a player isn’t even allowed to jump, but it’s full of puzzles and is a full-fledged adventure.
I removed 4 meaningless comments from the dataset, they either contained a word, a number, or a symbol, and one had been written even before the game was premiered. Let’s see what lies on the surface before moving to the sentiment analysis

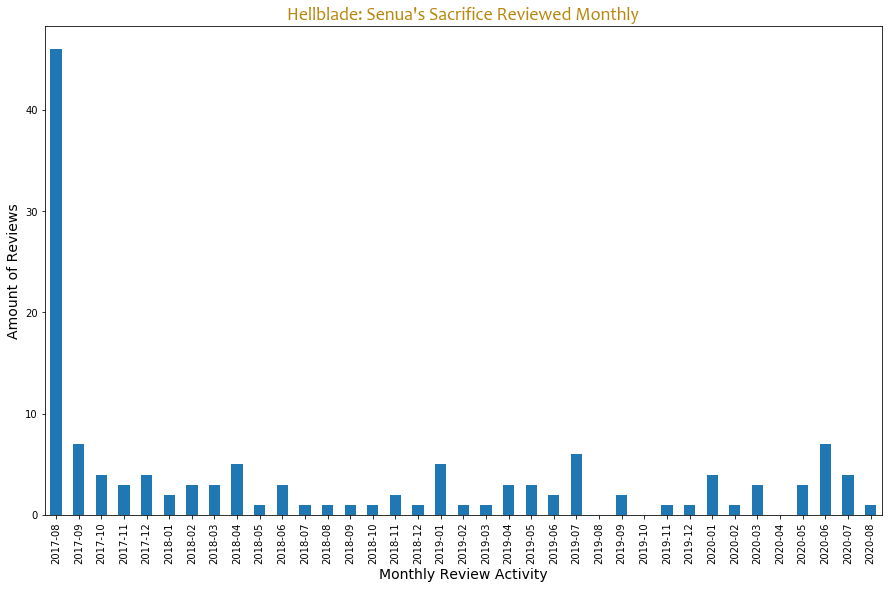
It probably doesn’t come as a surprise that most of the reviews were written within the month the product was released but I would expect the numbers to drop gradually and not significantly, I may need to collect reviews written to other games to see how it works.
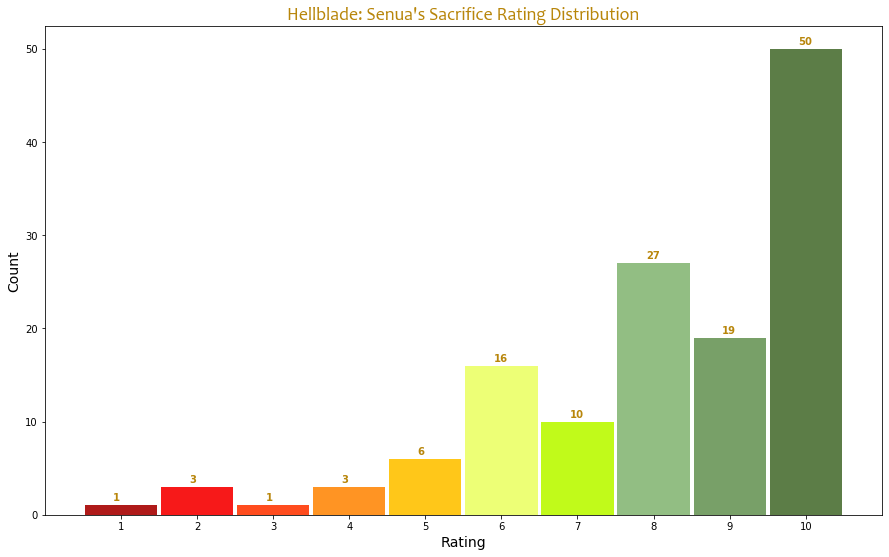
Then come the ratings. I rounded decimals with .5 to the closest higher whole number, and what’s lower to the closest lower one, as a score 7.4 was a total or aggregated score the game got from a player based on multiple factors required to rate the game by some site.

There are 50 reviews of Hellblade: Senua’s Sacrifice with a 10 out of 10 rating, more than 20 with around 8 and 9. 96 people of 136 highly enjoyed the game. There are 26 people who rated it above 6 and 14 who certainly didn’t like it.
Before I lemmatized the numbers I had loaded the stop words for Russian from nltk and added others like ‘very’, ‘own’, ‘which’, ‘can’, ‘whole’, ‘need’, which I believe were missing in the list. I also added words like ‘play’ and ‘game’ cause they’re abundant here. I found a function to preprocess Russian texts on Kaggle, it served well to lemmatize and tokenize the reviews. First it converts the texts in lowercase letters, then lemmatizes them with MyStem and if a word isn’t included in the stop words list and is neither an empty space nor a punctuation symbol.
I’ll just show what I got here and explain the underlying reasons of my actions in a different post:

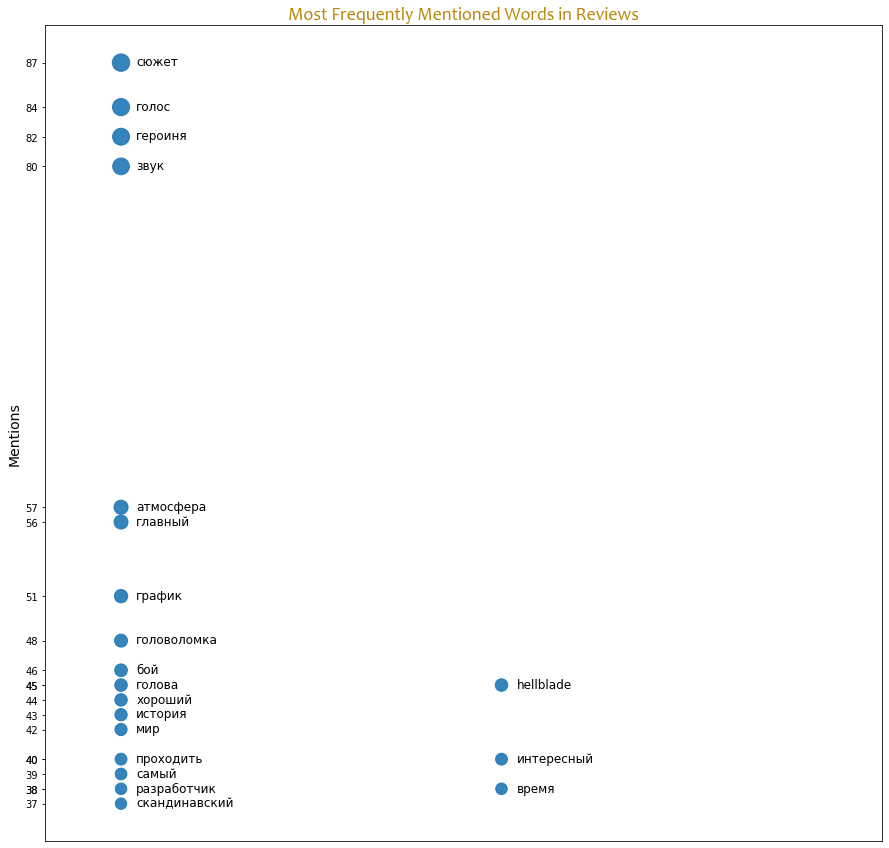
Here’s a word cloud of the words that people used to describe the game, the most common words get a particular weight corresponding to number of mentions so they’re highlighted in larger font sizes, but how precise is the word cloud generator and how many times are these words mentioned in there? I calculated the occurrences by using Counter from collections.
It turns out, it isn’t really precise, as you can see the words like Plot (сюжет), Voice (голос), Sound (звук) are the three top highlighted words in the word cloud, while according to the following chart the word Heroine (героиня) should meddle in between the Voice and Sound, it only took place in the right side of the word cloud and is even smaller than the words mentioned way less frequently.

I was looking for a nice way to visualize the list of the most common words (although a bar plot would do the job), I liked the idea of bubbles, so I came up with a solution: a scatterplot that hides behind the plot.
I got confused, I was thinking that ‘head’ (голова) appears in the list because it has been lemmatized from main (главный) but it wasn’t, I then remembered that Senua carries Dillion’s head on her belt as a container of his spirit. Isn’t it interesting that it has been mentioned 45 times, almost in one third of the reviews gathered? I find it an impressive artifact. It is also certain that people have been astonished by the sound engineers’ efforts to evoke the right feelings in players.
I then found a tutorial to calculate the compound sentiment using VADER, which is “a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media”. The only issue was that it didn’t really work with the language that reviews were written in, so I used Googletrans (“a free and unlimited python library that implemented Google Translate API”). Then the compound (or aggregated) score gap between positive and negative reviews seemed too small and I made an adjustment to the rule to consider the compound score from -25 to +25 as neutral reviews marked as 0. So now when the compound score is greater than 0.25 it should be a positive review valued as 1, when it’s lower than -25, it will be deemed to be a negative one and tagged as -1.
Here’s how it works:
print(df['review'][4])
print(df['review_translated'][4])
print(sentiment_analyzer_scores(df['review_translated'][4]))
на любителя, для меня она унылая
for an amateur, for me she is sad
-1
The reviewer was rather meaning to say ‘dull’ but it works. One could say that the comment carries a negative sentiment. Now that VADER classified the reviews, I can visualize the appraisal.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
20% of 136 reviews are negative, 14% neutral, and the other 66% (90 reviews) carry an overall positive sentiment. Could I generalize to say that every 5th player didn’t like it or would it be an exaggeration? Sadly, I don’t have enough data to conduct a t-test but I believe that it’s high enough a number to take into account and possibly adjust the game to this audience.
Afterwards I divided the scores in two and tried to build a machine learning model to predict the rating from 1 to 5 and solve a multi-classification problem by creating TF-IDF matrices. All I got, obviously, was an underfit due to the small dataset size and an abundance of positive reviews. Yet I tested how additional stop words affect the Logistic Regression model and the F1 score (a harmonic mean of precision and recall) improved to 0.52.